So, lots of missiles and drones last few days, in Kyiv.
Putin is running very low on missiles, so it’s a case now of sitting through what’s remains being used up.
I’m working away, intensely, on the Redshift management product, the AMI/container.
Tomorrow should be the last day of initial dev work, which leaves the docs to write. The docs of course will lead to further dev work, but I’m aiming to get the AMI out to the first two test customers in the next three or so days.
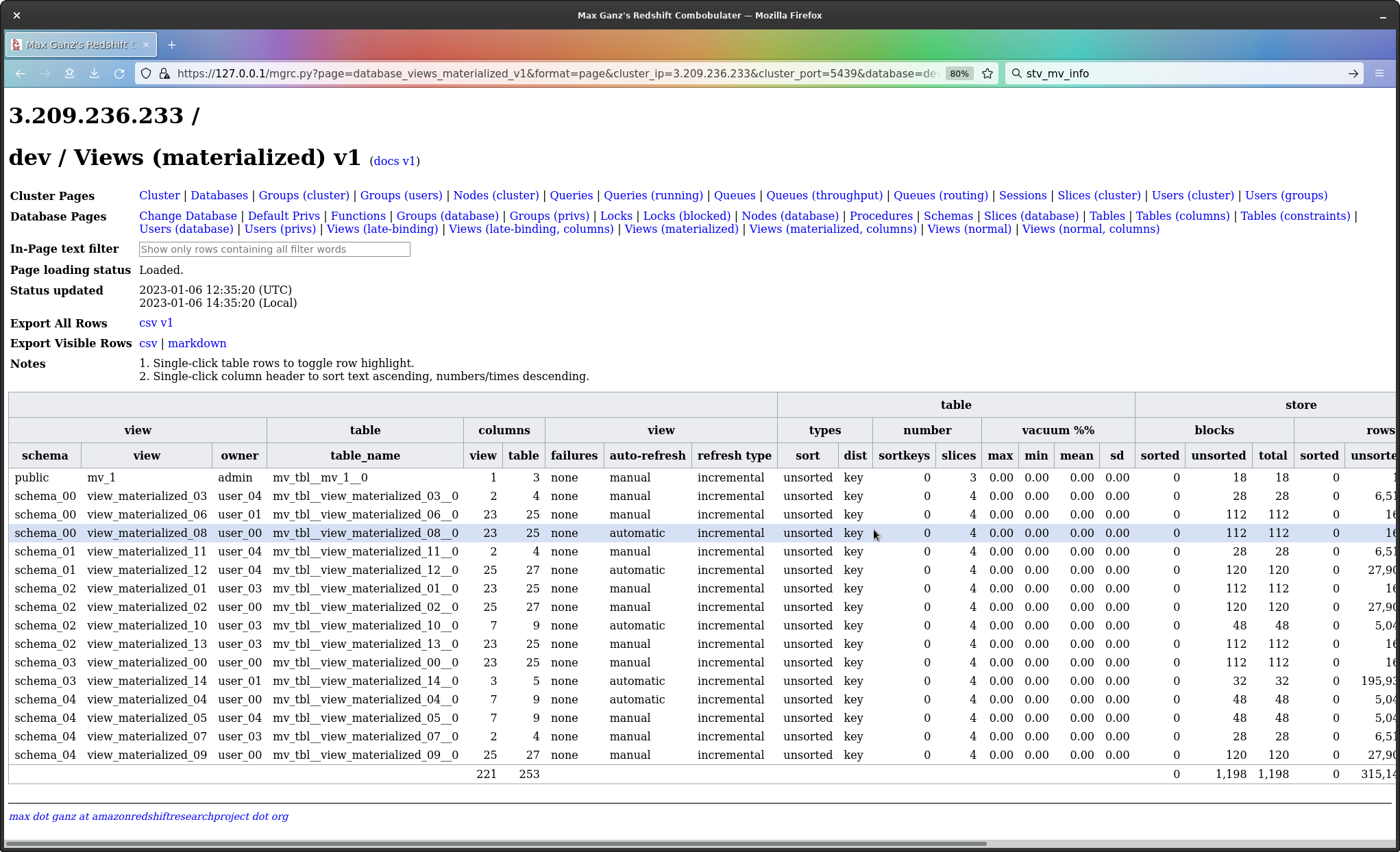
I’ve just added now a few more columns to the table information page; now have for tables their maximum, minimum, mean and standard deviation, for how vacuumed they are.
Vacuum is a per-slice property, and a table is as fast as the least vacuumed slice; the idea of a single percentage for vacuum is wrong.
What matters then is the minimum, and the other values are convenient ways to get perspective on that minimum, without needing to list one row per slice.
Quiet night last night.
I read 50 drones, but the drones I think are now a failed weapon; every single one was shot down. They move slowly, with no evasion. Probably the main effect of last night was keeping the air defence units from resting more than they would have. Cheap weapons - I’ve read 20k USD each - and a Stinger shoulder-launched round is about 100k USD, but there’s also radar guided gunfire (indigenous, and the Germans have been sending Gepard), which is extremely cost effective.
Given there’s only say 50 or 100 in a wave, the price difference in shooting them down is interesting but inconsequential. Relevant here is that the missiles (rather than drones) Putin is sending over cost a few million USD each.
The cruise missiles can and are being shot down, the ballistic missiles not (although that will change with Patriot); those come over and if they hit something they do, and if they miss, they miss, and my feeling is by and large they miss, and make a big hole in the ground, or blow up a residential apartment or hotel or office tower - like the one hit couple of months ago which I can see from my window - but when they do hit, it’s a power facility of some kind and it will be blown up.
A number of Asia-Pacific regions expressed degraded network
performance, in the last report. These regions have returned to normal,
except for ap-southeast-1, which remains degraded.
eu-central-1 dc2.large read benchmark
was 0.78s - normally it’s about 0.06s. This is the first time I’ve see
so large a deviation, and I would suspect this is a one-off fluke,
related to some issue with the cluster which was brought up for the
benchmark, rather than a region-wide issue.
eu-west-1 dc2.large read benchmark
dropped back to 0.14s, from 0.06s, which is how it used to be for a long
time before the widespread upgrades, across regions, to read
performance.
https://amazonredshift-observatory.ch/cross_region_benchmarks/index.html
In other news, I have been working for some months on a Redshift management product, an AMI/container. I’ve finished coding for the initial release, now writing the docs (and making whatever code changes emerge from that), and then it’s going out to the first two or three test victi^Husers :-)
This is an actual, pay-money-for-it product, but the money from it is going to the Ukrainian military.
Read ’em and weep, ladies and gentlemen.
Materialized views, with information on the underlying table - number of sorted/unsorted/total blocks and rows, rows inserted/deleted, bytes processed, least vacuumed slice, etc, etc.
I may be wrong, but I suspect a lot of people are about to find out their materialized views are highly unsorted.
(You’ll note in the screenshot the table name appears to be directly
derived from the view name. This is in fact the case only for quite
short names. With longer names, you get a table name like for example
this mv_tbl__aaaaaaaa_5111155189316119755__0. I use
pg_depends to find the dependency the view has on its
table.)
So, we start by thinking about roles in Postgres, because in Postgres they’re done simply and correctly and knowing how they should work makes it easier to understand what’s in Redshift.
In Postgres, it used to be (up to version 8.1) there were users and groups, and these were separate, first-class types in the database. Users could belong to groups, and both users and groups could hold privileges. A user held their own privileges, plus those of any group they were a member of. Groups could not be members of groups.
After 8.1, there were only roles. A user is really a role; a group is really a role. The only property that makes a “user” special is that its a role which is allowed to log into the server. So now it’s roles, all the way down - a role can belong to a role, a role can hold privileges, and a role holds the privileges of any roles it belongs to. All the existing operations on users and groups, although they are for compatibility still supported, actually now perform operations on groups. `
Lovely - pure, simple, utterly flexible, easy to reason about.
Now we come to Redshift and it’s detective time. The system tables in
Redshift, a lot of them, are not accessible to users. I’m figuring this
out by looking at what the GRANT command can do, and such
information as I can obtain from the system tables.
It looks to me like users and groups remain separate, first-class types in the database, but now we have roles as well. Users are not roles, groups are not roles, and life is about to get complicated.
It looks to me like roles are collections of privileges. Roles can be granted other roles, so you can chain them together, but that’s it.
So what we have looks to be this;
Groups I think have been superseded. A role can do everything a group does, and roles can be granted to other roles - which is the same as saying you have groups which belong to other groups.
There’s another issue, though, which are the privileges themselves.
Before roles came to Redshift, the privileges available were as follows;
| priv |
|---|
| delete |
| drop |
| insert |
| reference |
| select |
| temporary |
| update |
| usage |
These, except for drop which is new (late 2022) and
Redshift specific, are a subset of the classic Postgres privileges, and
control access to objects in the database.
With roles come a bunch of new privileges but these new privileges can only be granted to roles.
These new privileges are important - they provide control over Redshift functionality at a granular level, and they are needed for practical, pain-free cluster administration.
| priv |
|---|
| alter datashare |
| alter default privileges |
| alter table |
| alter user |
| analyze |
| cancel |
| create datashare |
| create library |
| create model |
| create or replace external function |
| create or replace function |
| create or replace procedure |
| create or replace view |
| create role |
| create schema |
| create table |
| create user |
| drop datashare |
| drop function |
| drop library |
| drop model |
| drop procedure |
| drop role |
| drop schema |
| drop table |
| drop user |
| drop view |
| truncate table |
| vacuum |
I can find no documentation at all about what these
privileges do - all there is, is guessing from their names, and
experimentation. The names may seem to obviously indicate function, but
there’s more to a privilege than that - for example,
create table, what happens about the schema? with
Postgres-style privileges, a user must hold usage on the
schema, to be able to use the create privilege on the
schema to create tables in that schema. What happens with the
Redshift-style privileges about that?
Another question I can immediately ask also is what happens about
creating temporary tables? Postgres-style privileges require the
temporary privilege on the database.
Having experimented a bit, it looks to me like there is a completely new privilege model here, which is totally independent from the Postgres-style privileges.
For example, holding create table is enough to create
tables in any schema. The Postgres-style privilege
usage is not required, and no other Redshift-style
privilege is necessary. I’ve also just checked what happens with
temporary tables - the Redshift-style privilege
create table also grants the capability to create temporary
tables.
These Redshift-style privileges have a totally different access model to the Postgres-style privileges.
If you start using Redshift-style privileges in parallel with Postgres-style privileges, I think you’re going to experience unintended consequences. Running two independent access models concurrently is asking for trouble.
I think your Postgres habits are going to be hard to forget, and so you’re going to think things are happening when they are not, particularly so since there’s no documentation for the new access model, and also no functionality to provide a report on what capabilities a user has, given the Redshift-style and Postgres-style privileges the user holds.
So where does this leave us?
The implementation of role is a hack, not the real deal, but it’s an important and functional hack, as roles can be granted to roles, and roles come with a new set of very useful privileges.
Roles are the new group. Groups are superseded by roles; everything you did with a group, you can now do with a role, but roles can take the new privileges (which I here am calling the Redshift-style privileges, as opposed to the previously existing Postgres-style privileges) as well as the existing privileges, and be granted to other roles.
Roles are the only way to grant Redshift-style privileges, as Redshift-style privileges cannot be granted to users or groups.
The access model of the Redshift-style privileges is wholly undocumented and completely different to the access model of the Postgres-style privileges, but both can be used concurrently. I would advise, in the strongest possible terms, not to mix any privileges which allow data access or privilege modification. For this, use either the Redshift-style privileges only, or the Postgres-style privileges only. Not both.
Postgres-style privileges are stored in the
[prefix]acl columns in the various system tables for each
type of privilege bearing object. In Postgres, where users and groups
are roles, privilege information is still stored wholly in these columns
- what’s changed is that before, the names specified were for users or
groups, where-as now, they’re only for roles.
In Redshift, the [prefix]acl columns are unchanged. They
still contain and only contain the Postgres-style privileges, and the
names still refer to users and groups, and there are still no system
tables which provide information on Postgres-style privilege (I have an
AMI now out with the first two test users, which amongst many others
capabilities, provides this information, for both users and groups -
this is a real, actual, you-gotta-pay-for-it product, but all the money
from it is going to the Ukrainian military).
The new Redshift-style privileges are stored separately, in new system tables.
The new privileges are not in fact offering completely new
functionality. It was already possible, using the “run as” functionality
of procedures, to write a procedure which offered, say,
VACUUM, which ran as a superuser, where the privilege to
run that procedure was granted to those users who were to be given the
capability to run VACUUM.
However, obviously, the new arrangement is a lot more convenient.
All in all then, the fundamental approach to privilege management remains unchanged, except roles replace groups. So, before, we would never grant privileges to users, only to groups, and we would control privilege allocation to users by adding or removing them from groups. Now, we still never grant privileges to users, but now we rather than granting privileges to groups, we grant them to roles, and control privilege allocation to users by granting roles to users.
What we have that’s new are the Redshift-style privileges, and that roles can be granted to roles, giving more flexibility.

They do this in dark, milk, and with and without nuts.
Oh God :-)
So, I wrote in the previous blog post about the new Redshift-style privileges that they have a completely different access model to the existing Postgres-style privileges.
I realised this is true in a way I had not originally realised.
With Postgres, you issue privileges on objects to a recipient (which is a user, group or the group-like object public).
So I might issue select on a table to a group.
If I then make a new table, no one else has any privileges on it - I would need to grant them.
With the new Redshift-style privileges, it’s not like this.
These privileges are global and apply to everything that exists, always.
If I grant create table to a role (and then that role to
a user), that user can now create tables, always, in all schemas, both
those which existed at the time the grant was made, and in the
future.
AWS call the new Redshift-style privileges “system permissions”.
I can now infer that what is meant by this is that the privileges are system-wide and always-on. These are, as it were, fragments of the superuser role. If you’re superuser, you can do anything, always. If you have a new Redshift-style privilege, you can perform that privilege on anything, always.
So I’ve started working on SQL to present role privs - and the very first thing I find, I mean THE FIRST THING on running a query - undocumented privileges. They’re shown in the system tables, I can grant them, they’re not in the docs.
That means far as I can tell there is no actual list of the
new privs. The GRANT page does not list the privs I’m
seeing.
If this is really the case, this is ridiculous. This is brand new functionality. What’s going on?
I’ve started working tonight with the system tables for roles, to present some easy to use pages in the Combobulator (the AMI I’m working on for managing Redshift).
I may be wrong, but it looks to me like the implementation of roles has just buggered up a metric ton of system tables, because the implementation of roles in the system tables is using leader node only functions.
SELECT derived_table1.role_id, derived_table1.role_name, derived_table1.granted_role_id, derived_table1.granted_role_name
FROM ( SELECT "chain".childroleid AS role_id, "role".rolname::character varying(128) AS role_name, "chain".parentroleid AS granted_role_id, granted_role.rolname::character varying(128) AS granted_role_name
FROM pg_role_chain "chain"
JOIN ( SELECT pg_role.rolid, pg_role.rolname
FROM pg_role
WHERE (EXISTS ( SELECT 1
FROM pg_identity
WHERE pg_identity.useid = "current_user_id"() AND pg_identity.usesuper = true)) OR has_system_privilege("current_user"()::name, 'ACCESS SYSTEM TABLE'::text) OR user_is_member_of("current_user"()::name, pg_role.rolname) OR "current_user_id"() = pg_role.rolowner) "role" ON "chain".childroleid = "role".rolid
JOIN ( SELECT pg_role.rolid, pg_role.rolname
FROM pg_role
WHERE (EXISTS ( SELECT 1
FROM pg_identity
WHERE pg_identity.useid = "current_user_id"() AND pg_identity.usesuper = true)) OR has_system_privilege("current_user"()::name, 'ACCESS SYSTEM TABLE'::text) OR user_is_member_of("current_user"()::name, pg_role.rolname) OR "current_user_id"() = pg_role.rolowner) granted_role ON "chain".parentroleid = granted_role.rolid) derived_table1;That’s the code for svv_role_grants.
See user_is_member_of()? leader node only. Same for
has_system_privilege().
So system privs here look to be implemented in view code,
rather than in the database kernel. This is like, what? it looks like a
sign that the kernel is unmaintainable - can’t be changed to
accept this new functionality - but there are other privs such as
drop table, which are used on user tables, which are not
views, so they must be in the kernel, some way or another. I
wonder if they’re actually tapping into the existing Postgres-style
privs, under the hood?
In any event, this means you cannot join these system tables to any normal Redshift tables, or use them in queries which recruit worker nodes in any way - which is what I was trying to do. I can get round this in the AMI, I’ll query each table individually, write each back to a temp table, then issue my main query, so, fine, but what I’m seeing here is a real hack of implementation.
ap-northeast-2, dc2.large networking is
slow again; 7.14s vs the usual 4s or so.
ap-south-1, dc2.large disk-read-write
is fast; 3s vs the usual 4.5s or so.
eu-central-1, dc2.large disk-read is
normal again; 0.06s, vs the most unusual 0.78s the previous
benchmark.
eu-west-1, dc2.large disk-read is back
to normal; the usual 0.06s, rather than 0.14s.
us-east-1, dc2.large networking has
returned to normal; 4.5s or so, rather than the 7.68s of the previous
benchmark.
us-east-2, dc2.large disk-read-write is
fast; 3s, vs the usual 4.25s or so. Unusually, there’s a noticeable
change in the processor benchmark, from the recent usual 2.9s or so to
3.22s. The processor benchmark is normally extremely stable.
us-west-2, dc2.large disk-read-write is
fast; 3.1s vs the usual 4s to 5s, although this benchmark has quite high
variance in this region.
http://www.amazonredshift-observatory.ch/cross_region_benchmarks/index.html
There has been now one full year of weather reports :-)
Something odd seems to be going on with the function which produces information about late-binding columns.
A week or two ago, if I had a session open to Redshift, and issued a
query, I would get the results I expected; but if I ran the same query
over a psycopg2 connection, I would get no results.
A few days after I noticed that, it fixed itself.
Except maybe not quite - what I am seeing now is if I am connected
directly, plsql, and I issue a query, I get the results I
expect - 209 rows.
If I issue the same query over psycopg2, I get 107
rows.
So, in the early days of the site I published a dump of the system tables, on a per-Redshift version basis.
The code which produced the dump was ditzy - it just produced the pages which were uploaded.
Back in about May 2022, I rewrote the backend so it would archive the contents of certain system tables (those needed to generate the pages about the system tables), and the existing pages fell into disuse, because they were a lot of manual work to maintain.
I’ve just pushed the third test release of the Combobulator (AMI for Redshift management) to the first two test users, and it’s the first fully working version, which is great, and I’ve had a day or two off, just to kick back - and I’ve finally now written the code to dump HTML pages from the data I’ve been accumulating over the last seven or eight months.
The current pages then are a first effort, which gets the pages up to date with the current release (and releases since May 2022). I’m already able to do something I wanted to do before, but couldn’t, which is show the size in kilobytes of the text for the SQL of views.
Where I have the source data now in my own database, I can improve these pages over time.
The dumps are useful in two particular ways; firstly, the official docs are maintained by hand, not automated, and they’re ten years old - the system table pages list columns which no longer exist, and have not been updated to list columns which now exist, have incorrect data types and so on. My feeling (I’ve not run any code to compute a number) is they are now about 20% incorrect. Secondly, they provide easy and direct access to the SQL code for the system views. This is important because the system table docs are a veneer only, and so you find you need to look into the SQL to understand what you’re seeing. However, AWS have started censoring the SQL of more recent views - they’ve put code in to specifically block viewing the SQL. This isn’t very widespread yet, but it’s bloody stupid as there’s no up-side to it and interferes with the ability to system admins to manage their clusters.
You can find the new pages here;
https://www.amazonredshift-observatory.ch/system_table_tracker/index.html
Home 3D Друк Blog Bring-Up Times Cross-Region Benchmarks Email Forums Mailing Lists Redshift Price Tracker Redshift Version Tracker Replacement System Tables Reserved Instances Marketplace Slack System Table Tracker The Known Universe White Papers